UC San Diego Undergraduates Forge New Area of Bioinformatics
Showing posts with label Latest Information. Show all posts
Showing posts with label Latest Information. Show all posts
What Is the HapMap?
What Is the HapMap?
This is an article that recently appeared on The International HapMap project, http://www.hapmap.org/.
The HapMap is a catalog of common genetic variants that occur in human beings. It describes what these variants are, where they occur in our DNA, and how they are distributed among people within populations and among populations in different parts of the world. The International HapMap Project is not using the information in the HapMap to establish connections between particular genetic variants and diseases. Rather, the Project is designed to provide information that other researchers can use to link genetic variants to the risk for specific illnesses, which will lead to new methods of preventing, diagnosing, and treating disease.
Figure 1: When DNA sequences on a part of chromosome 7 from two random individuals are compared, two single nucleotide polymorphisms (SNPs) occur in about 2,200 nucleotides.
The DNA in our cells contains long chains of four chemical building blocks -- adenine, thymine, cytosine, and guanine, abbreviated A, T, C, and G. More than 6 billion of these chemical bases, strung together in 23 pairs of chromosomes, exist in a human cell. (Seehttp://www.dnaftb.org/dnaftb/ for basic information about genetics.) These genetic sequences contain information that influences our physical traits, our likelihood of suffering from disease, and the responses of our bodies to substances that we encounter in the environment.
The genetic sequences of different people are remarkably similar. When the chromosomes of two humans are compared, their DNA sequences can be identical for hundreds of bases. But at about one in every 1,200 bases, on average, the sequences will differ (Figure 1). One person might have an A at that location, while another person has a G, or a person might have extra bases at a given location or a missing segment of DNA. Each distinct "spelling" of a chromosomal region is called an allele, and a collection of alleles in a person's chromosomes is known as a genotype.
Differences in individual bases are by far the most common type of genetic variation. These genetic differences are known as single nucleotide polymorphisms, or SNPs (pronounced "snips"). By identifying most of the approximately 10 million SNPs estimated to occur commonly in the human genome, the International HapMap Project is identifying the basis for a large fraction of the genetic diversity in the human species.
For geneticists, SNPs act as markers to locate genes in DNA sequences. Say that a spelling change in a gene increases the risk of suffering from high blood pressure, but researchers do not know where in our chromosomes that gene is located. They could compare the SNPs in people who have high blood pressure with the SNPs of people who do not. If a particular SNP is more common among people with hypertension, that SNP could be used as a pointer to locate and identify the gene involved in the disease.
However, testing all of the 10 million common SNPs in a person's chromosomes would be extremely expensive. The development of the HapMap will enable geneticists to take advantage of how SNPs and other genetic variants are organized on chromosomes. Genetic variants that are near each other tend to be inherited together. For example, all of the people who have an A rather than a G at a particular location in a chromosome can have identical genetic variants at other SNPs in the chromosomal region surrounding the A. These regions of linked variants are known as haplotypes (Figure 2).
In many parts of our chromosomes, just a handful of haplotypes are found in humans. [See The Origins of Haplotypes.] In a given population, 55 percent of people may have one version of a haplotype, 30 percent may have another, 8 percent may have a third, and the rest may have a variety of less common haplotypes. The International HapMap Project is identifying these common haplotypes in four populations from different parts of the world. It also is identifying "tag" SNPs that uniquely identify these haplotypes. By testing an individual's tag SNPs (a process known as genotyping), researchers will be able to identify the collection of haplotypes in a person's DNA. The number of tag SNPs that contain most of the information about the patterns of genetic variation is estimated to be about 300,000 to 600,000, which is far fewer than the 10 million common SNPs.
Once the information on tag SNPs from the HapMap is available, researchers will be able to use them to locate genes involved in medically important traits. Consider the researcher trying to find genetic variants associated with high blood pressure. Instead of determining the identity of all SNPs in a person's DNA, the researcher would genotype a much smaller number of tag SNPs to determine the collection of haplotypes present in each subject. The researcher could focus on specific candidate genes that may be associated with a disease, or even look across the entire genome to find chromosomal regions that may be associated with a disease. If people with high blood pressure tend to share a particular haplotype, variants contributing to the disease might be somewhere within or near that haplotype.

This is an article that recently appeared on The International HapMap project, http://www.hapmap.org/.
The HapMap is a catalog of common genetic variants that occur in human beings. It describes what these variants are, where they occur in our DNA, and how they are distributed among people within populations and among populations in different parts of the world. The International HapMap Project is not using the information in the HapMap to establish connections between particular genetic variants and diseases. Rather, the Project is designed to provide information that other researchers can use to link genetic variants to the risk for specific illnesses, which will lead to new methods of preventing, diagnosing, and treating disease.
Figure 1: When DNA sequences on a part of chromosome 7 from two random individuals are compared, two single nucleotide polymorphisms (SNPs) occur in about 2,200 nucleotides.
The DNA in our cells contains long chains of four chemical building blocks -- adenine, thymine, cytosine, and guanine, abbreviated A, T, C, and G. More than 6 billion of these chemical bases, strung together in 23 pairs of chromosomes, exist in a human cell. (Seehttp://www.dnaftb.org/dnaftb/ for basic information about genetics.) These genetic sequences contain information that influences our physical traits, our likelihood of suffering from disease, and the responses of our bodies to substances that we encounter in the environment.
The genetic sequences of different people are remarkably similar. When the chromosomes of two humans are compared, their DNA sequences can be identical for hundreds of bases. But at about one in every 1,200 bases, on average, the sequences will differ (Figure 1). One person might have an A at that location, while another person has a G, or a person might have extra bases at a given location or a missing segment of DNA. Each distinct "spelling" of a chromosomal region is called an allele, and a collection of alleles in a person's chromosomes is known as a genotype.
Differences in individual bases are by far the most common type of genetic variation. These genetic differences are known as single nucleotide polymorphisms, or SNPs (pronounced "snips"). By identifying most of the approximately 10 million SNPs estimated to occur commonly in the human genome, the International HapMap Project is identifying the basis for a large fraction of the genetic diversity in the human species.
For geneticists, SNPs act as markers to locate genes in DNA sequences. Say that a spelling change in a gene increases the risk of suffering from high blood pressure, but researchers do not know where in our chromosomes that gene is located. They could compare the SNPs in people who have high blood pressure with the SNPs of people who do not. If a particular SNP is more common among people with hypertension, that SNP could be used as a pointer to locate and identify the gene involved in the disease.
However, testing all of the 10 million common SNPs in a person's chromosomes would be extremely expensive. The development of the HapMap will enable geneticists to take advantage of how SNPs and other genetic variants are organized on chromosomes. Genetic variants that are near each other tend to be inherited together. For example, all of the people who have an A rather than a G at a particular location in a chromosome can have identical genetic variants at other SNPs in the chromosomal region surrounding the A. These regions of linked variants are known as haplotypes (Figure 2).
In many parts of our chromosomes, just a handful of haplotypes are found in humans. [See The Origins of Haplotypes.] In a given population, 55 percent of people may have one version of a haplotype, 30 percent may have another, 8 percent may have a third, and the rest may have a variety of less common haplotypes. The International HapMap Project is identifying these common haplotypes in four populations from different parts of the world. It also is identifying "tag" SNPs that uniquely identify these haplotypes. By testing an individual's tag SNPs (a process known as genotyping), researchers will be able to identify the collection of haplotypes in a person's DNA. The number of tag SNPs that contain most of the information about the patterns of genetic variation is estimated to be about 300,000 to 600,000, which is far fewer than the 10 million common SNPs.
Once the information on tag SNPs from the HapMap is available, researchers will be able to use them to locate genes involved in medically important traits. Consider the researcher trying to find genetic variants associated with high blood pressure. Instead of determining the identity of all SNPs in a person's DNA, the researcher would genotype a much smaller number of tag SNPs to determine the collection of haplotypes present in each subject. The researcher could focus on specific candidate genes that may be associated with a disease, or even look across the entire genome to find chromosomal regions that may be associated with a disease. If people with high blood pressure tend to share a particular haplotype, variants contributing to the disease might be somewhere within or near that haplotype.
BioXseed India Launches Biotech Finishing School
Certified Advanced Program in Genomics and Proteomics

Aristogene Biosciences is known in the industry for most authentic and practical training in the field of Biosciences. It has a well equipped 8000 sq.ft lab with the required infrastructure to support Research & Training activities. Aristogene also has an
independent R & D and process development wing, which is involved in the development of many products.
BioXseed is the Life Sciences wing of 64 Squares Consulting, a leading HR Services company with various top notch clients.
Course Content:
- Tools in Genetic Engineering & Microbiology- Pure culture techniques, Working with phages, Cloning fundamentals, PCR
- Cloning & Expression of Gene and Bioinformatics -Know how of complete cloning process, Important Bioinformatics tools, Knowledge ofvector host systems, DNA manipulation techniques, Expression and analysis of clones
- Immunotechnology- Immunoprecipitaion and Agglutination techniques, Use of immunotechniques in diagnosis, ELISA, Blotting techniques
- Protein Purification Techniques-Various chromatography techniques, Protein analysis by SDS-PAGE and western blotting, Enzymology.
- Polymerase chain reaction & Hybridization techniques-A strong foundation for PCR based experiments - Gene amplification, RAPD analysis and related experiments, PCR - RFLP and related experiments, Southern hybridization.
- Tools and techniques for success at workplace - Acquire the skills required for your all-round effectiveness like
o Understanding corporate environment,
o Getting your strengths noticed,
o Creative problem solving skills
o Business Etiquettes and personal grooming and the like.
Faculty for the Program:
- Sudha with 19 years of experience specializing in Protein and nucleic acid purification, process improvement, product development, Phages, Plasmids, Restriction enzymes, and recombinant technology, and cancer cell biology.
- Vasudha with 20 years of experience specializing in Cloning and Expression of restriction and modifying enzymes
- Dr CR Subhashini with 15 years of experience specializing in Molecular Diagnostics & Immunology.
- Ruskinn D with 11 years of experience specializing in Microbiology, Manufacturing & Instrumentation.
- Shuchi Shukla with 9 years Corporate HR experience in high-end niche technology sectors.
- Visiting Faculty from Industry.
Unique Features of this Advanced Program in Genomics and Proteomics:
- Unique opportunity to enhance employability.
- Advanced course that matches industry requirements with contents generally not covered in regular courses at college.
- Student-Industry-Academia Interface. Industry Leaders will be invited to share real life experience with students.
- A strong emphasis on hands-on laboratory training.
- Training under the guidance of scientists with more than two decades of industry experience.
- Proven track record in Industry Integration Program.
- Limited enrollments with an individualized industrial learning environment.
- Counseling services to students.
- Curriculum and experienced speakers carefully selected to emphasize practical approaches.
- Special Placement assistance program including Resume writing, Interview tips, Mock Interviews etc
Key Dates for the Program:
Travel & accommodation assistance can be provided for outstation students.
For more information Please fill out this Contact form or email at info@bioxseedindia.com ; shuchi@64sqs.com ; lifesc@64sqs.com Or
Call at +91-9845215711 (Bangalore)/ +91-9953100729 (Delhi).
Download Application Form
Download Information Brochure
Apply Online
ICMR to launch low-cost swine flu diagnostic kit
A low-cost diagnostic tool kit that can detect the swine flu virus in just five minutes is being developed by the Indian Council for Medical Research, a top official has said
The tool based on polynial chain reaction method is a simple kit to detect the virus that has so far claimed over 700 lives across the country. It will be released in a month or two, Deputy Director General of ICMR M Rajamani said here.
"It is a simple kit and can detect the virus in five minutes. It can be sent to villages for spot tests also," he told reporters yesterday.
The price would range from Rs 1,800 to Rs 2,000 while the existing imported ones cost Rs 7,000, Rajamani, who was here to participate in a conference of Medical Anthropology, said.
Attend and Present Your Research Work @ ICPEP - 4 held at NBRI, Lucknow
Most of the environmental concerns faced by the developed countries following industrial revolution and resultant economic boom and consumerism in the past are now spreading to the developing countries as well. Among the scourges faced by mankind today, environmental pollution is in the forefront. In the greater part of the last century, it was the fast pace of industrialization, galloping demand for energy and reckless exploitation of natural resources, in developed countries, that were mainly responsible for creating the problem of environmental pollution.
Disciplines of Conference
1. Bioindication & Bioremediation
2. Environment & Biotechnology
3. Environmental education, Mass awareness and Legislation
4. Environmental Impact Assessment and Eco-auditing
5. Environment and Biodiversity
6. Plant Responses to Environmental Pollution
7. Climate change - Plant productivity and food Security
8. Contemporary environmental issues;
Palaeo-Environment
Environmental impact on cultural heritage
Environmental systems and Disaster management
Bio-pollutants
Indoor pollutants
Bio-energy
Sustainable agriculture
Human settlements
Abstract of Paper:
The Abstract not exceeding one A-4 page is to be typed in “Times New Roman” 12 pt normal font, single line spacing and should include:
Title of Paper in BLOCK letter
Name of author(s) in italics with an asterisk (*) marked against the name of the presenting author,
5 to 6 key words
Main body
Author(s)’ primary institutional affiliations using superscript numerals including full address of all the authors (s) up to town and country and their E-mail IDs.
Last date for submission of abstract is 31st July 2010.
Registration Details
Students - Rs. 1500/-
Accompanying Person - Rs.1500/-
Member ISEB - Rs.2500/-
Non Member - Rs. 3000/-
Registration Form
Accomodation
Lucknow has several 3-5 star hotels of international standards as well as many good economy/budget hotels. Delegates may arrange their own accommodation.
Correspondence
All correspondence should be addressed to;
The Organizing Secretaries (ICPEP-4),
International Society of Environmental Botanists
National Botanical Research Institute
Rana Pratap Marg
Lucknow-226001, India.
E.mail - isebnbrilko@sify.com / isebmail@gmail.com
Ph Nos - +91-522-2297821 (Direct) +91-522-2205831 to 2205835 (PBX) Extn. 821
1. Bioindication & Bioremediation
2. Environment & Biotechnology
3. Environmental education, Mass awareness and Legislation
4. Environmental Impact Assessment and Eco-auditing
5. Environment and Biodiversity
6. Plant Responses to Environmental Pollution
7. Climate change - Plant productivity and food Security
8. Contemporary environmental issues;
Palaeo-Environment
Environmental impact on cultural heritage
Environmental systems and Disaster management
Bio-pollutants
Indoor pollutants
Bio-energy
Sustainable agriculture
Human settlements
The Abstract not exceeding one A-4 page is to be typed in “Times New Roman” 12 pt normal font, single line spacing and should include:
Title of Paper in BLOCK letter
Name of author(s) in italics with an asterisk (*) marked against the name of the presenting author,
5 to 6 key words
Main body
Author(s)’ primary institutional affiliations using superscript numerals including full address of all the authors (s) up to town and country and their E-mail IDs.
Last date for submission of abstract is 31st July 2010.
Students - Rs. 1500/-
Accompanying Person - Rs.1500/-
Member ISEB - Rs.2500/-
Non Member - Rs. 3000/-
Registration Form
Lucknow has several 3-5 star hotels of international standards as well as many good economy/budget hotels. Delegates may arrange their own accommodation.
All correspondence should be addressed to;
The Organizing Secretaries (ICPEP-4),
International Society of Environmental Botanists
National Botanical Research Institute
Rana Pratap Marg
Lucknow-226001, India.
E.mail - isebnbrilko@sify.com / isebmail@gmail.com
Ph Nos - +91-522-2297821 (Direct) +91-522-2205831 to 2205835 (PBX) Extn. 821
1st International Conference on Bioinformatics and Systems Biology @ Annamalai University, Tamil Nadu
The Annamalai University is a unitary, teaching and residential university.The Department of Zoology, Anna University with sponsership from ICMR, DSt, DBT ir organizing a 3-day International Conference on Bioinformatics and Systems Biology in the month of February 2010.
Scope of the Conference |
Themes of the Conference
Papers are solicited on, but not limited to, the following topics:
• Agricultural bioinformatics
• Bioinformatics databases & Bioinformatics of diseases
• Chemoinformatics
• Computational genomics and proteomics
• DNA Assembly, clustering and mapping
• DNA Bar coding and Bioinformatics
• Drug discovery & Data mining, Database ontologies
• Gene expression and microarrays, Gene identification
• Hidden Markov models
• Immunoinformatics of diseases, Molecular sequence analysis
• Neuroinformatics
• Phylogeny reconstruction algorithms
• Protein structure prediction and modelling
• Parallel algorithms for biological analysis , Simulation and system dynamics
Bioinformatics and Systems Biology 2010 invites high-quality original full papers on any topic related to Bioinformatics and System Biology. The submitted papers must have not been published or under the consideration for publication in any other journal or conference with formal proceedings. All accepted papers will have to be presented by one on the authors at the conference.
The online submission system will be open from December 2, 2009 to January 20, 2010.
Registration
All the participants and their accompanying members are requested to register by paying the necessary registration fees. Participants are requested to fill the enclosed registration form (Photo copy may be used) and mail it to the Organizing Secretary along with the copies of abstract and registration fees payable by DD from a Nationalized bank in favour of “The Registrar, Annamalai University” Payable at Annamalainagar (or) Chidambaram.
Accomodation
Limited accommodation will be arranged by the organizers in the University guest house / Hostel etc. (First come first serve basis).
Important Dates
Paper submission open December 2, 2009
Paper submission deadline January 20, 2010
Paper acceptance decision January 28, 2010
Poster submission open December 30, 2009
Poster submission deadline January 28, 2010
Poster acceptance decision January 30, 2010
Registration open December 2, 2009
Early-bird registration upto January 30, 2010
Conference Feb 19 - 21, 2010
Organizing Secretary
Dr.SABESAN, Ph.D.
Prof. & Wing Head, Dept. of Zoology, D.D.E.
Annamalai University,Annamalainagar-608 002, Tamil Nadu,India
E-mail : sabesan1956@gmail.com, sabesan_muthukumar@yahoo.com
sabesan_in@redifmail.com, Mobile : 09994932234
Your own Bioinformatics workstation using VigyaanCD
VigyaanCD at
http://www.vigyaancd.org/
has a nice collection of bioinformatics software and is worth downloading. It will boot directly from the CD and needs very little linux expertise as the X-windows system is almost like windows.
R (programming language)
The R Project for Statistical Computing
R is a language and environment for statistical computing and graphics. It is a GNU project which is similar to the S language and environment which was developed at Bell Laboratories (formerly AT&T, now Lucent Technologies) by John Chambers and colleagues. R can be considered as a different implementation of S. There are some important differences, but much code written for S runs unaltered under R.
R provides a wide variety of statistical (linear and nonlinear modelling, classical statistical tests, time-series analysis, classification, clustering, ...) and graphical techniques, and is highly extensible. The S language is often the vehicle of choice for research in statistical methodology, and R provides an Open Source route to participation in that activity.
R Screenshots
 MacOS X RAqua desktop
MacOS X RAqua desktop Unix desktop
Unix desktopGraphics Examples
 box and whisker plots
box and whisker plots piechart
piechart pairs plot
pairs plot coplot
coplot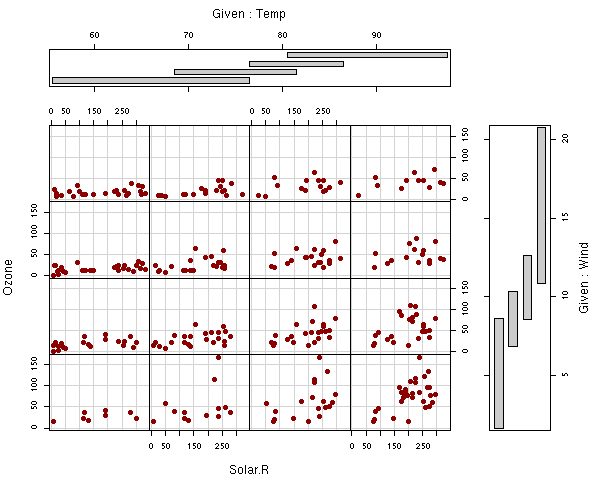 another coplot that shows nice interactions
another coplot that shows nice interactions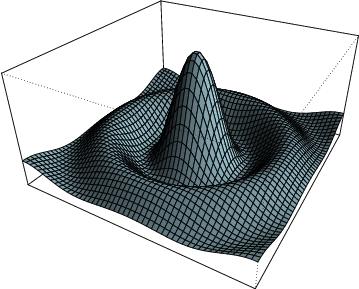 3d plot of a surface
3d plot of a surface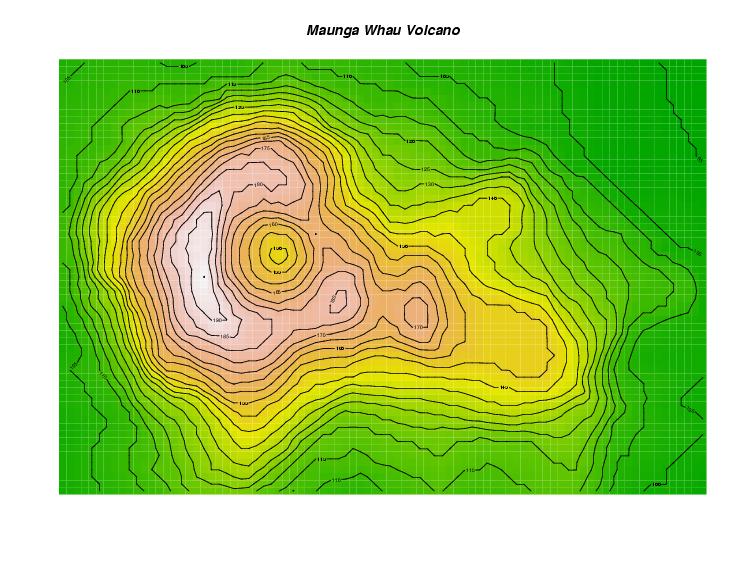
 image and 3d plot of a volcano
image and 3d plot of a volcano mathematical annotation in plots
mathematical annotation in plots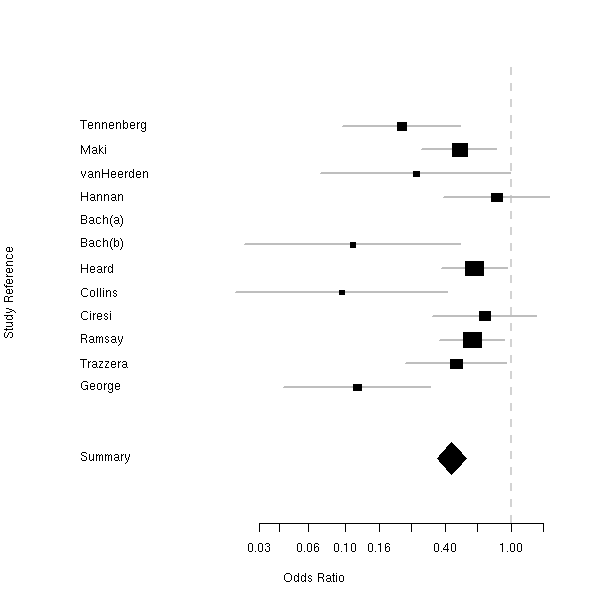 forest plot (plot of confidence intervals in a meta-analysis)
forest plot (plot of confidence intervals in a meta-analysis)All images on this site are Copyright (C) the R Foundation and may be reproduced for any purpose provided they are credited to the R statistical software using an attribution like "(C) R Foundation, from http://www.r-project.org".
One of R's strengths is the ease with which well-designed publication-quality plots can be produced, including mathematical symbols and formulae where needed. Great care has been taken over the defaults for the minor design choices in graphics, but the user retains full control.
The R environment
R is an integrated suite of software facilities for data manipulation, calculation and graphical display. It includes
- an effective data handling and storage facility,
- a suite of operators for calculations on arrays, in particular matrices,
- a large, coherent, integrated collection of intermediate tools for data analysis,
- graphical facilities for data analysis and display either on-screen or on hardcopy, and
- a well-developed, simple and effective programming language which includes conditionals, loops, user-defined recursive functions and input and output facilities.
The term "environment" is intended to characterize it as a fully planned and coherent system, rather than an incremental accretion of very specific and inflexible tools, as is frequently the case with other data analysis software.
R, like S, is designed around a true computer language, and it allows users to add additional functionality by defining new functions. Much of the system is itself written in the R dialect of S, which makes it easy for users to follow the algorithmic choices made. For computationally-intensive tasks, C, C++ and Fortran code can be linked and called at run time. Advanced users can write C code to manipulate R objects directly.
Many users think of R as a statistics system. We prefer to think of it of an environment within which statistical techniques are implemented. R can be extended (easily) via packages. There are about eight packages supplied with the R distribution and many more are available through the CRAN family of Internet sites covering a very wide range of modern statistics.
R has its own LaTeX-like documentation format, which is used to supply comprehensive documentation, both on-line in a number of formats and in hardcopy.
Subscribe to:
Comments (Atom)
















